| Tool Mentor: CCMDB - Identify Configuration Items |
 |
|
| Related Elements |
|---|
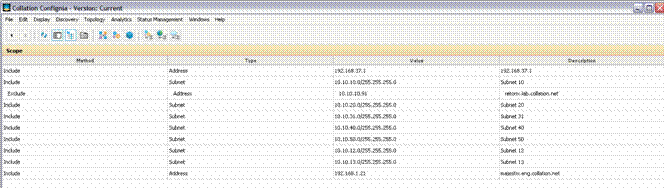
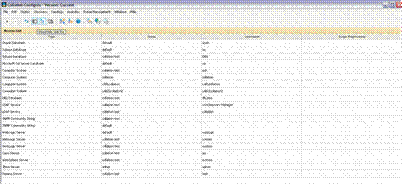
ContextTool mentors explain how a tool can perform tasks, which are part of ITUP processes and activities. The tasks are listed as Related Elements in the Relationships section. You can see the details of how processes and activities are supported by this tool mentor, by clicking the links next to the icons: DetailsThe IBM® Tivoli® Application Dependency Discovery Manager (TADDM), a component of the Change and Configuration Management Database (CCMDB), is an agent-free tool for discovering CIs and provides complete and detailed application maps of business applications and supporting infrastructure, including cross-tier dependencies, run-time configuration values, and complete change history. There are two inputs that must be defined before discovery can occur: Scope and Access.
The TADDM discovery process can be executed on demand, as part of a schedule, or driven by externally triggered events. Upon discovery initiation, the TADDM discovery engine proceeds through a multi-step process:
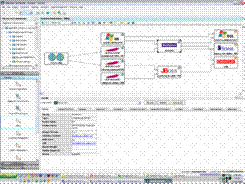
Upon completion of discovery, TADDM processes the discovered component data to populate the CMDB and generate a topological representation of the infrastructure. Subsequent discovery runs update the database and topologies, while maintaining a comprehensive change history of the infrastructure configuration and dependencies. The result is an intuitive application map and deep configuration details as shown in Figure 3.
For more informationFor more information about this tool, click the tool name IBM Tivoli change and Configuration Management Database at the top of this page. |
©Copyright IBM Corp. 2005, 2008. All Rights Reserved. |